Previous generative spoken language modeling work have used discrete units
that discard most of the prosodic information, failing to leverage
prosody for better comprehension and generation.
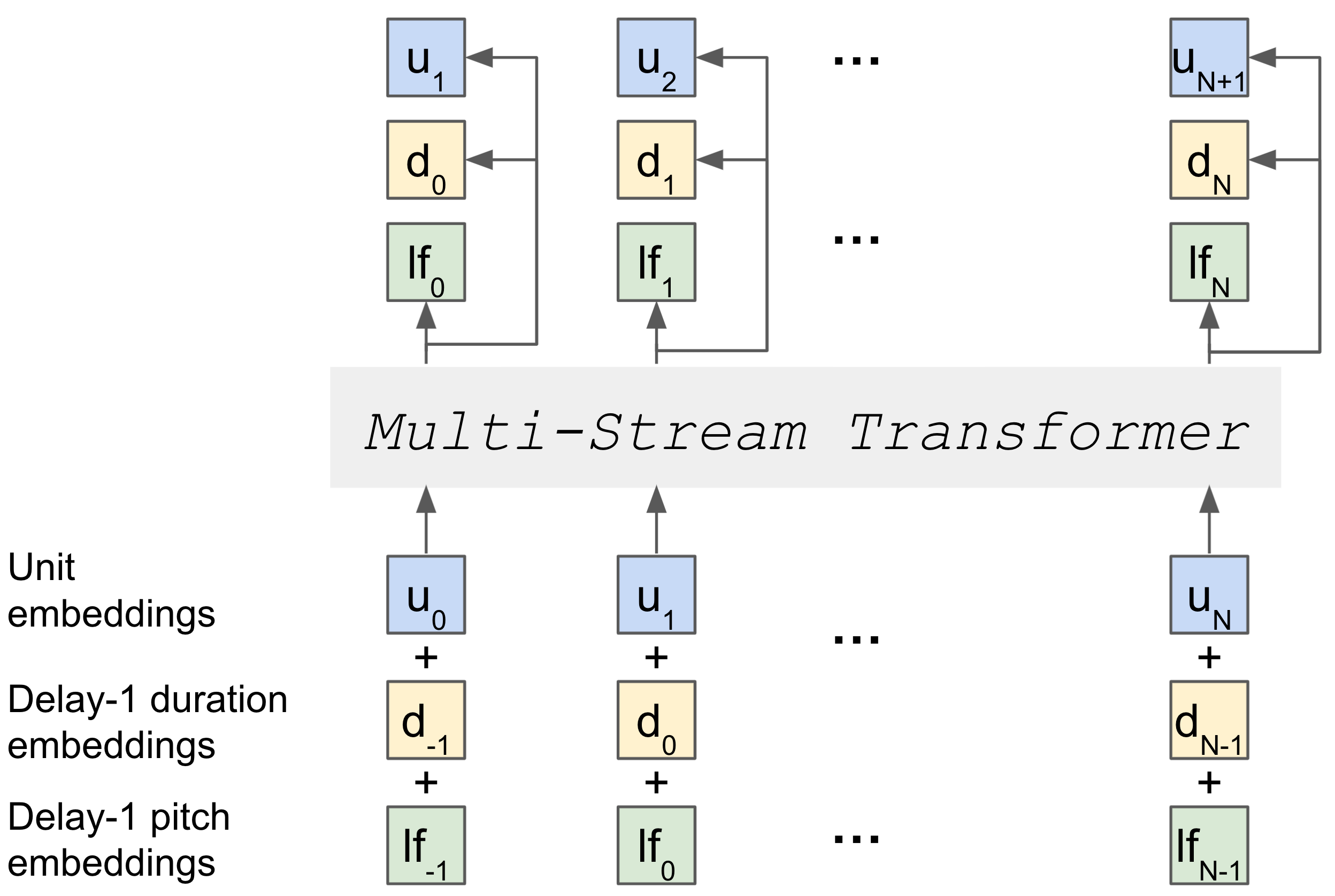
We introduce a prosody-aware generative spoken language model
(pGSLM). It is composed of a multi-stream transformer language
model (MS-TLM) of speech, represented as discovered unit and
prosodic feature streams, and an adapted HiFi-GAN model
converting MS-TLM outputs to waveforms. Experimental results show that
the pGSLM can utilize prosody to improve both prosody and
content modeling, and also generate more natural, meaningful, and coherent speech given a spoken prompt.
* equal contribution
Conditional Speech Generation Examples
In conditional generation, the system encodes a waveform prompt into a sequence of tuples of pseudo-text units, normalized F0, and duration.
This sequence is then fed to the multi-stream language model (MS-TLM) from which a continuation is sampled in an auto-regressive manner.
The result is then passed to the decoder to produce a new waveform. The entire pipeline is trained without supervision or text.
Below are prompts, ground-truth continuations (resynthesised), and samples from our models.
✅: model has prosody (unit duration and F0) as a part of its input
❌: model has no prosody in its input
Prompt
Resynthesis
Continuous Prosody
Quantized Prosody
❌
✅
❌
✅
Samples
In the first task, speech generation, MS-TLM models generate continuation of a speech prompt.
In the second task, prosody continuation, the models generate prosody streams (duration and normalized F0), while
the stream of units is fixed to that of the ground-truth utterance. For comparison, we additionally provide original utterances
as-is and resynthesised using the HiFi-GAN vocoder used by MS-TLM.
✅: model has prosody (unit duration and F0) as a part of its input