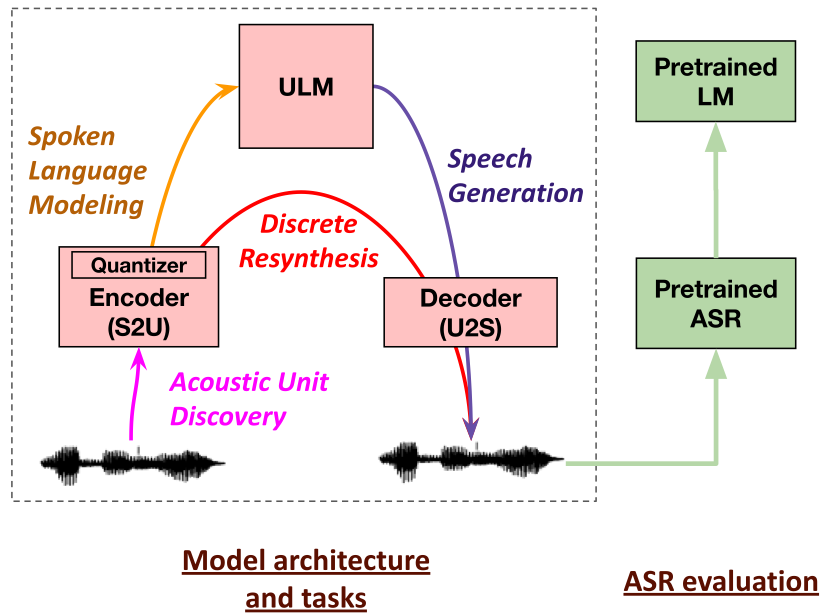
We introduce generative spoken language modeling, the task of jointly learning the acoustic and linguistic characteristics of a language from raw audio (without text), and a set of metrics to automatically evaluate the learned representations at acoustic and linguistic levels for both encoding and generation.
We set up baseline systems consisting of a discrete speech encoder (returning pseudo-text units), a generative language model (trained on pseudo-text), and a speech decoder (generating a waveform from pseudo-text) and validate the proposed metrics with human evaluation.
Across unsupervised speech encoders (CPC, wav2vec 2.0, HuBERT), we find that the number of discrete units (50, 100, or 200) matters in a task-dependent and encoder-dependant way, and that some combinations approach text-based topline systems.
* Equal contribution.
Conditional Examples
In conditional generation, the system encodes a waveform prompt
into pseudo-text, which is fed to the language model
from which a continuation is sampled. The resulting extended pseudo-text is then fed to the decoder to produce a new waveform.
The entire pipeline is trained without supervision or
text. Below are samples from our worst and best models,
compared to a supervised system
trained from text.
Prompts
Unsupervised (worst)
Unsupervised (best)
Supervised
Encoder
---
LogMel
HuBERT
Characters
# of units
---
100
100
28
0
1
Unconditional Examples
In unconditional generation, a pseudo-text is sampled from the
language model and synthetized into a waveform.
Unsupervised (worst)
Unsupervised (best)
Supervised
Encoder
LogMel
HuBERT
Characters
# of units
100
100
28
0
1
Samples
More samples are provided below, as a function of the dataset
used to train the voice, the number of units and the generation
task. Four different encoder types can be compared (CPC, HuBERT,
LogMel and Wav2Vec2) and a supervised character-based system.