Generative Spoken Dialogue Language Modeling
Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky,
Paden Tomasello, Robin Algayres, Benoit Sagot, Abdelrahman Mohamed, Emmanuel Dupoux
In Transactions of the Association for Computational Linguistics
[Paper]
[Code]
[Blog]
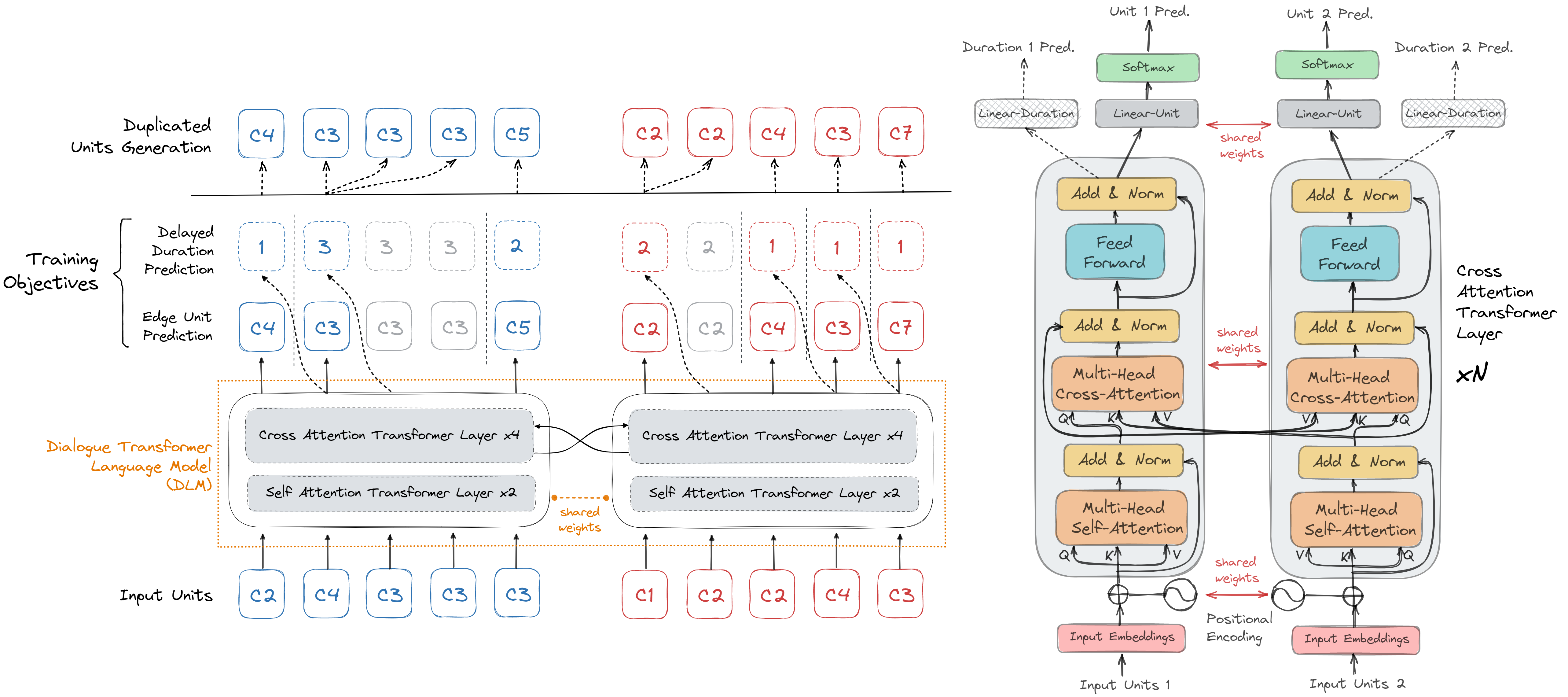
We introduce dGSLM, the first "textless" model able to generate audio samples of naturalistic spoken dialogues.
It uses recent work on unsupervised spoken unit discovery coupled with a dual-tower transformer architecture with
cross-attention trained on 2000 hours of two-channel raw conversational audio (Fisher dataset) without any text or
labels. We show that our model is able to generate speech, laughter and other paralinguistic signals in the two
channels simultaneously and reproduces more naturalistic and fluid turn taking compared to a text-based cascaded model.
Conditional Examples
In conditional generation, the system encodes a stereo waveform prompt
into two parallel streams of discrete units (or pseudo-text), which are fed to the Dialogue Language Model (DLM) system,
a system attending to both unit streams with the help of cross-attention.
The DLM model then generates new pseudo-text and feed them to the decoder to produce a new waveform.
The entire pipeline is trained without supervision or
text.
Below are generation samples from our best model,
compared to the ground truth continuation and from a cascaded model (ASR+text-LM+TTS). Note that the synthesized speakers are different from the original ones,
but we deliberately choose the speakers with the same gender as in original speech.
You will hear a ding sound at the end of the prompt duration.
| ID |
original speech |
synthesized speech continuation |
| Prompt |
Ground Truth |
dGSLM (Continuation 1) |
dGSLM (Continuation 2) |
Cascaded Continuation |
| 0 |
|
|
|
|
|
| 1 |
|
|
|
|
|
Unconditional Examples
In unconditional generation, two parallel streams of pseudo-text are sampled from the
DLM and synthetized into a waveform.
Generation 1 (dGSLM)
Generation 2 (dGSLM)
Conditional Samples from All Algorithms
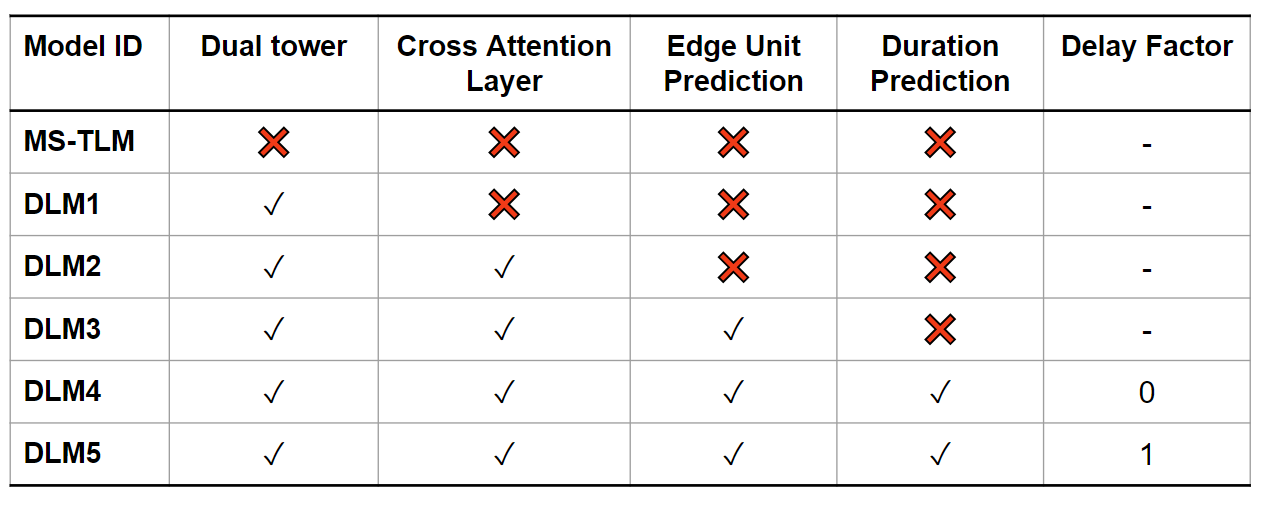
More conditional samples are provided below, with all the language models studied in the paper.
The specifications of all models are listed below
You will also hear a
ding sound at the end of the prompt duration.
Loading......